Производительность С++ STL regex
Столкнулся недавно с простой задачей - нужно было найти позицию открывающегося тега <body> в HTML странице. Не долго думая я решил использовать регулярные выражения, через минуту у меня родился регексп <body[^>]*>. Все работало хорошо, пока дело не дошло до тестирования на больших объемах данных.
Я решил создать тестовое приложение, дабы замерить скорость работы regex_search:
#include <regex>
#include <iostream>
int find_position_re(std::string &text, std::regex ®ex)
{
std::smatch match;
if (std::regex_search(text, match, regex))
{
return match.position() + match.length();
}
return -1;
}
int main(int argc, char* argv[])
{
std::string text(1024 * 10000, ' ');
text.append("<body>asdasd</body>");
std::regex regex("<body[^>]*>");
float start = (float)clock() / CLOCKS_PER_SEC;
find_position_re(text, regex);
float end = (float)clock() / CLOCKS_PER_SEC;
std::cout << end - start << std::endl;
return 0;
}На поиск в 10 мегабайтной строке потребовалось почти 200 миллисекунд, что не очень быстро, учитывая, что тестировалось на свежем MacBook Pro.
Для интереса я скомпилировал код с помощью GCC и Clang, написал аналогичный код на Python:
import re
import timeit
def find_position_re(text, regex):
match = regex.search(text)
if match:
return match.start()
return -1
text = ' ' * (1024 * 10000)
text += '<body>asdasd</body>'
regex = re.compile("<body[^>]*>")
print(timeit.timeit(lambda: find_position_re(text, regex), number=1))И на JavaScript:
function find_position_re(text, regex) {
return text.search(regex);
}
var text = '';
for (var i = 0; i < 1024 * 10000; i++) {
text += ' ';
}
text += '<body>asdasd</body>';
var regex = new RegExp('<body[^>]*>');
console.time('test');
find_position_re(text, regex);
console.timeEnd('test');Тестовое приложение на Node.js оказалось в 3, а на Python в 31 раз быстрее, чем на Visual Studio 2013.
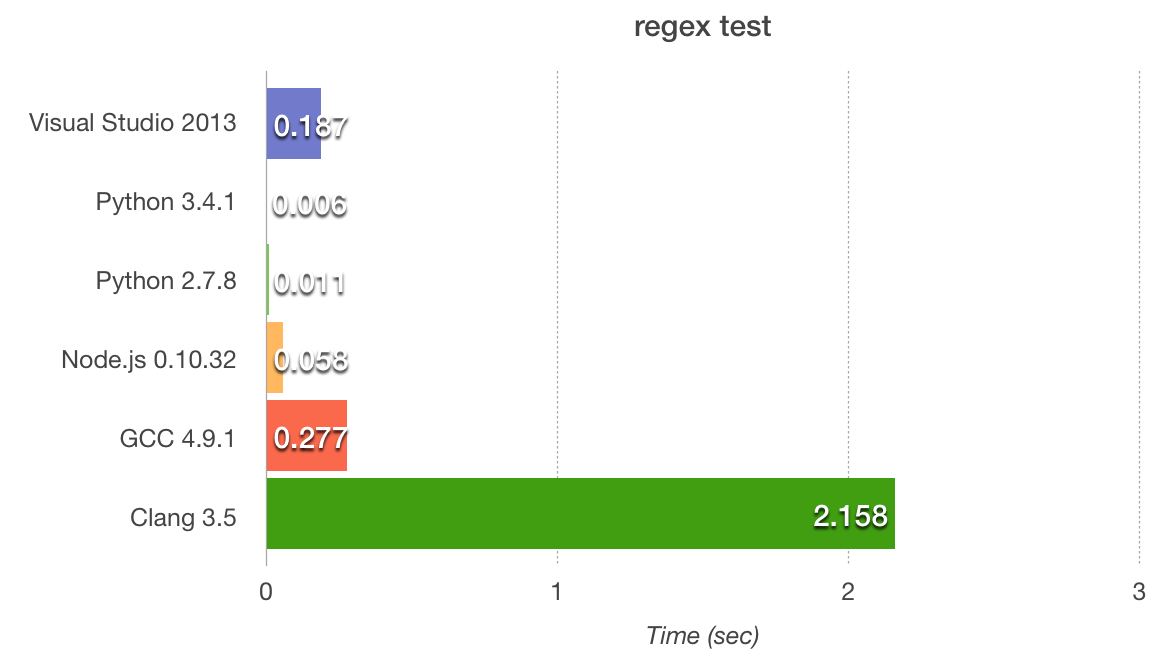
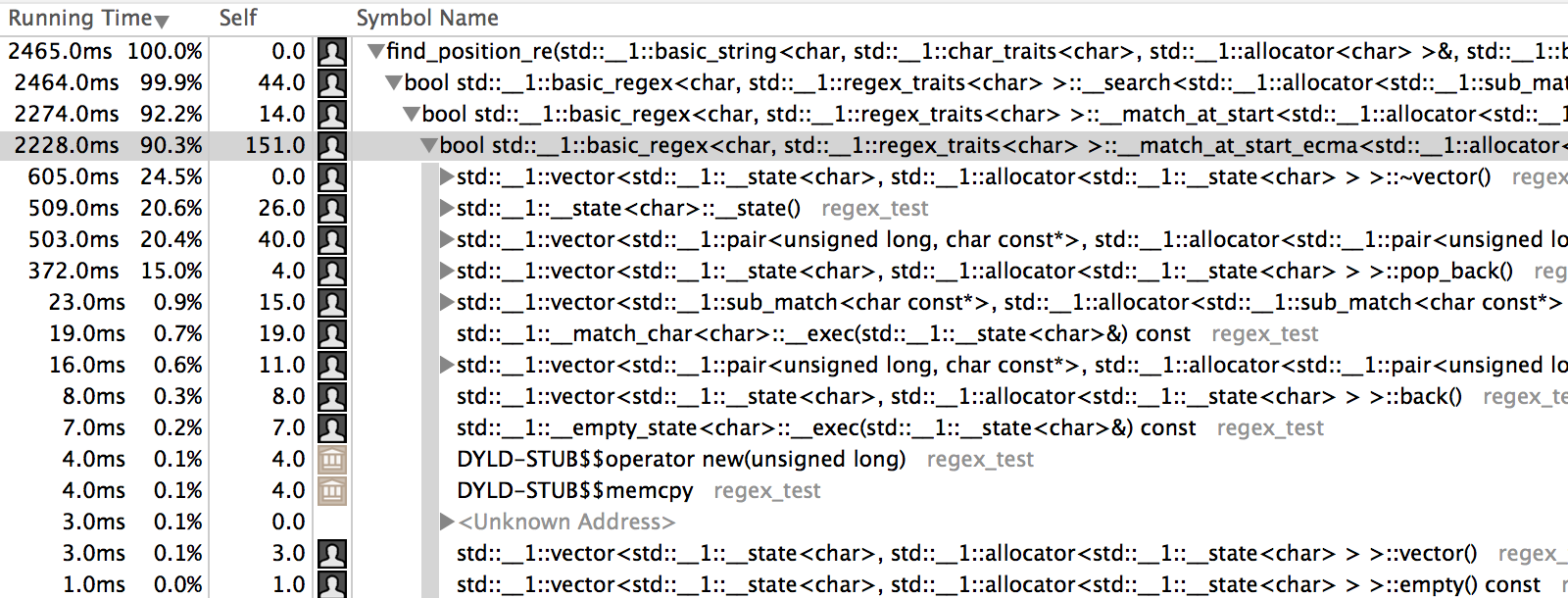
Clang меня абсолютно разочаровал результатом. Немного покрутив флаги компилятора, я понял, что дело совсем не в них. Я запустил профайлер, чтобы найти узкое место. Им оказалась функция __match_at_start_ecma, которая вызывалась на каждую итерацию поиска:
template <class _CharT, class _Traits>
template <class _Allocator>
bool
basic_regex<_CharT, _Traits>::__match_at_start_ecma(
const _CharT* __first, const _CharT* __last,
match_results<const _CharT*, _Allocator>& __m,
regex_constants::match_flag_type __flags, bool __at_first) const
{
vector<__state> __states;
__node* __st = __start_.get();
if (__st)
{
__states.push_back(__state());
__states.back().__do_ = 0;
__states.back().__first_ = __first;
__states.back().__current_ = __first;
__states.back().__last_ = __last;
__states.back().__sub_matches_.resize(mark_count());
__states.back().__loop_data_.resize(__loop_count());
__states.back().__node_ = __st;
__states.back().__flags_ = __flags;
__states.back().__at_first_ = __at_first;
do
{
__state& __s = __states.back();
if (__s.__node_)
__s.__node_->__exec(__s);
switch (__s.__do_)
{
case __state::__end_state:
__m.__matches_[0].first = __first;
__m.__matches_[0].second = _VSTD::next(__first, __s.__current_ - __first);
__m.__matches_[0].matched = true;
for (unsigned __i = 0; __i < __s.__sub_matches_.size(); ++__i)
__m.__matches_[__i+1] = __s.__sub_matches_[__i];
return true;
case __state::__accept_and_consume:
case __state::__repeat:
case __state::__accept_but_not_consume:
break;
case __state::__split:
{
__state __snext = __s;
__s.__node_->__exec_split(true, __s);
__snext.__node_->__exec_split(false, __snext);
__states.push_back(_VSTD::move(__snext));
}
break;
case __state::__reject:
__states.pop_back();
break;
default:
#ifndef _LIBCPP_NO_EXCEPTIONS
throw regex_error(regex_constants::__re_err_unknown);
#endif
break;
}
} while (!__states.empty());
}
return false;
}При длине строки в тысячу символов на моих тестовых данных эта функция вызывалась тысячу раз, что влекло за собой тысячу созданий, push_back, pop_back и уничтожений std::vector и соответственно тысячу динамических выделений и освобождений памяти.
В моем конкретном случае для моего регулярного выражения проблему можно решить таким костылем:
int find_position_re(std::string &text, std::regex ®ex)
{
std::string text2 = text.substr(text.find("<body"));
std::smatch match;
if (std::regex_search(text2, match, regex))
{
return match.position() + match.length();
}
return -1;
}Это ускоряет работу примерно в 100 раз. Интересно, что аналогичный трюк в Python и Node.js влияет на скорость негативно.
Поддержка регулярных выражений в STL была добавлена в С++11 и реализована только в последних версиях компиляторов. Остается надеяться, что проблему производительности исправят в новых версиях.
Какой из этого всего можно сделать вывод? Производительность в первую очередь это не низкоуровневые (или новомодные) языки программирования и быстрые процессоры, а эффективные алгоритмы.